Dude is available on Github: https://github.com/roniemartinez/dude
Yesterday, I open-sourced Dude and released it on PyPI. Dude was inspired by Flask syntax allowing Python developers to write a web scraper in in just a few lines of code.
Like Flask, Dude has an easy-to-learn syntax. You can build a web scraper with just a single decorated function.
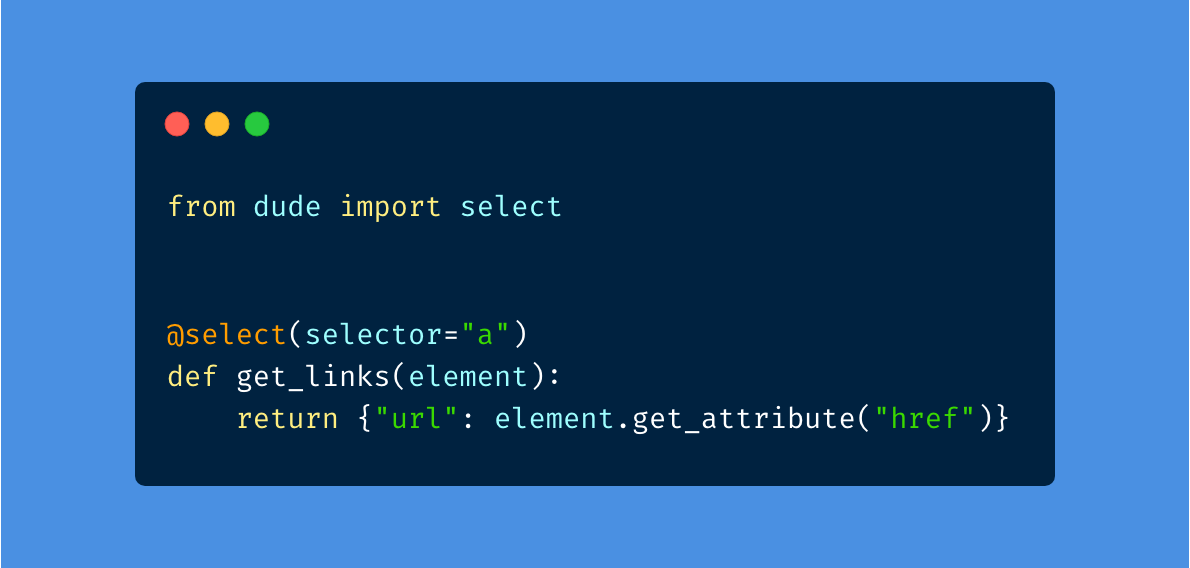
Here is the minimal example that can scrape all the links/URLs from a website.
from dude import select
@select(selector="a")
def get_link(element):
return {"url": element.get_attribute("href")}
Features
The first version 0.1.0 comes with the following features:
- Simple Flask-inspired design - build a scraper with decorators.
- Uses Playwright API - run your scraper in Chrome, Firefox and Webkit and leverage Playwright's powerful selector engine supporting CSS, XPath, text, regex, etc.
- Data grouping - group related scraping data.
- URL pattern matching - run functions on specific URLs.
- Priority - reorder functions based on priority.
- Setup function - enable setup steps (clicking dialogs or login).
- Navigate function - enable navigation steps to move to other pages.
- Custom storage - option to save data to other formats or database.
- Async support - write async handlers.
Installation
Dude is available on PyPI and can be easily installed using pip.
pip install pydudeIn addition, you will need to install the browser binaries for Playwright, also from command line.
playwright installBasic Usage
As a demo, simply copy the minimal example to a file named example.py.
# example.py
from dude import select
@select(selector="a")
def get_link(element):
return {"url": element.get_attribute("href")}
To start scraping, run the following from terminal:
dude scrape --url "<replace-with-url>" example.py --output output.jsonThis should create a file named output.json containing your scraped data. Just an example, running this command against this website will result in the following.
[
{
"page_number": 1,
"page_url": "https://ron.sh/",
"group_id": 4492219664,
"group_index": 0,
"element_index": 0,
"url": "https://ron.sh"
},
{
"page_number": 1,
"page_url": "https://ron.sh/",
"group_id": 4492219664,
"group_index": 0,
"element_index": 1,
"url": "https://ron.sh/"
},
{
"page_number": 1,
"page_url": "https://ron.sh/",
"group_id": 4492219664,
"group_index": 0,
"element_index": 2,
"url": "https://ron.sh/about/"
},
{
"page_number": 1,
"page_url": "https://ron.sh/",
"group_id": 4492219664,
"group_index": 0,
"element_index": 3,
"url": "https://ron.sh/privacy-policy/"
},
{
"page_number": 1,
"page_url": "https://ron.sh/",
"group_id": 4492219664,
"group_index": 0,
"element_index": 4,
"url": "https://ron.sh/terms-of-service/"
},
// ...more output here
]Advanced Usage
Details on several advanced features and how to use them can be found in the Github repository: https://github.com/roniemartinez/dude#advanced-usage
Final Thoughts
Dude is at a very early stage. I encourage everyone interested in web scraping to contribute by opening bug reports, feature requests, pull requests and discussions. Your help is highly appreciated!



